NARAYANAMOORTHI - MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers
Here you can read online NARAYANAMOORTHI - MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2021, genre: Children. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers
- Author:
- Genre:
- Year:2021
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
NARAYANAMOORTHI: author's other books
Who wrote MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers? Find out the surname, the name of the author of the book and a list of all author's works by series.






MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
MACHINE LEARNING  CONTENTS UNIT I INTRODUCTION TO MACHINE LEARNING UNIT II DECISION THEORY UNIT III CLUSTERING & REGRESSION UNIT IV MULTILAYER PERCEPTRONS UNIT V LOCAL MODELS UNIT I INTRODUCTION TO MACHINE LEARNING Machine learning - examples of machine learning applications - Learning associations - Classification - Regression - Unsupervised learning - Supervised Learning - Learning class from examples - PAC learning - Noise, model selection and generalization - Dimension of supervised machine learning algorithm. Definition of Machine learning: Well posed learning problem: " A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."(Tom Michel) "Field of study that gives computers the ability to learn without being explicitly programmed". Learning = Improving with experience at some task - Improve over task T, - with respect to performance measure P, - based on experience E. E.g., Learn to play checkers - T : Play checkers - P : % of games won in world tournament - E: opportunity to play against self
CONTENTS UNIT I INTRODUCTION TO MACHINE LEARNING UNIT II DECISION THEORY UNIT III CLUSTERING & REGRESSION UNIT IV MULTILAYER PERCEPTRONS UNIT V LOCAL MODELS UNIT I INTRODUCTION TO MACHINE LEARNING Machine learning - examples of machine learning applications - Learning associations - Classification - Regression - Unsupervised learning - Supervised Learning - Learning class from examples - PAC learning - Noise, model selection and generalization - Dimension of supervised machine learning algorithm. Definition of Machine learning: Well posed learning problem: " A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E."(Tom Michel) "Field of study that gives computers the ability to learn without being explicitly programmed". Learning = Improving with experience at some task - Improve over task T, - with respect to performance measure P, - based on experience E. E.g., Learn to play checkers - T : Play checkers - P : % of games won in world tournament - E: opportunity to play against self 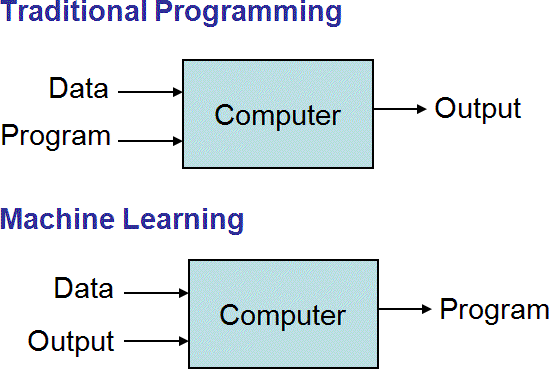 Examples of tasks that are best solved by using a learning algorithm: Recognizing patterns: Facial identities or facial expressions Handwritten or spoken words Medical images Generating patterns: Generating images or motion sequences (demo) Recognizing anomalies: Unusual sequences of credit card transactions Unusual patterns of sensor readings in a nuclear power plant or unusual sound in your car engine. Prediction: Future stock prices or currency exchange rates The web contains a lot of data. Tasks with very big datasets often use machine learning especially if the data is noisy or non-stationary.
Examples of tasks that are best solved by using a learning algorithm: Recognizing patterns: Facial identities or facial expressions Handwritten or spoken words Medical images Generating patterns: Generating images or motion sequences (demo) Recognizing anomalies: Unusual sequences of credit card transactions Unusual patterns of sensor readings in a nuclear power plant or unusual sound in your car engine. Prediction: Future stock prices or currency exchange rates The web contains a lot of data. Tasks with very big datasets often use machine learning especially if the data is noisy or non-stationary.
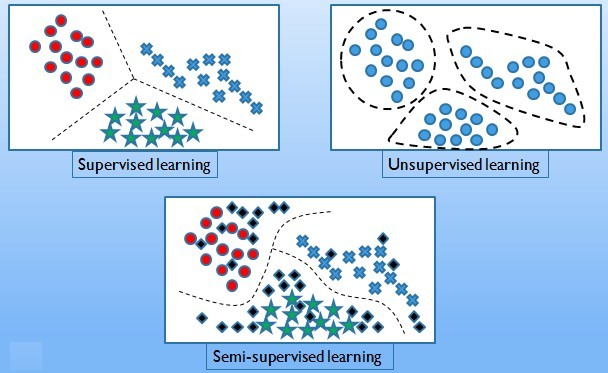
Spam filtering, fraud detection: The enemy adapts so we must adapt too. Recommendation systems: Lots of noisy data. Million dollar prize! Information retrieval: Find documents or images with similar content. Data Visualization: - Display a huge database in a revealing way Types of learning algorithms: Supervised learning
- Training data includes desired outputs. Examples include,
- Prediction
- Classification (discrete labels), Regression (real values)
- Training data does not include desired outputs, Examples include,
- Clustering
- Probability distribution estimation
- Finding association (in features)
- Dimension reduction
- Training data includes a few desired outputs
- Rewards from sequence of actions
- Policies: what actions should an agent take in a particular situation
- Utility estimation: how good is a state ( used by policy)
- No supervised output but delayed reward
- Credit assignment problem (what was responsible for the outcome)
- Applications:
- Game playing
- Robot in a maze
- Multiple agents, partial observability, ...
 Hypothesis Space One way to think about a supervised learning machine is as a device that explores a hypothesis space. Each setting of the parameters in the machine is a different hypothesis about the function that maps input vectors to output vectors.
Hypothesis Space One way to think about a supervised learning machine is as a device that explores a hypothesis space. Each setting of the parameters in the machine is a different hypothesis about the function that maps input vectors to output vectors. If the data is noise-free, each training example rules out a region of hypothesis space. If the data is noisy, each training example scales the posterior probability of each point in the hypothesis space in proportion to how likely the training example is given that hypothesis. The art of supervised machine learning is in: Deciding how to represent the inputs and outputs Selecting a hypothesis space that is powerful enough to represent the relationship between inputs and outputs but simple enough to be searched. Generalization The real aim of supervised learning is to do well on test data that is not known during learning. Choosing the values for the parameters that minimize the loss function on the training data is not necessarily the best policy. We want the learning machine to model the true regularities in the data and to ignore the noise in the data.
But the learning machine does not know which regularities are real and which are accidental quirks of the particular set of training examples we happen to pick. So how can we be sure that the machine will generalize correctly to new data? Training set, Test set and Validation set Divide the total dataset into three subsets: Training data is used for learning the parameters of the model. Validation data is not used of learning but is used for deciding what type of model and what amount of regularization works best. Test data is used to get a final, unbiased estimate of how well the network works. We expect this estimate to be worse than on the validation data. We could then re-divide the total dataset to get another unbiased estimate of the true error rate.
Learning Associations: Basket analysis: P ( Y | X ) probability that somebody who buys X also buys Y where X and Y are products/services. Example: P ( chips | beer ) = 0.7 // 70 percent of customers who buy beer also buy chips. We may want to make a distinction among customers and toward this,estimate P(Y|X,D) where D is the set of customer attributes, for example,gender, age, marital status, and so on, assuming that we have access to this information. If this is a bookseller instead of a supermarket, products can be books or authors. In the case of a Web portal, items correspond to links to Web pages, and we can estimate the links a user is likely to click and use this information to download such pages in advance for faster access. Classification: Example: Credit scoring Differentiating between low-risk and high-risk customers from their income and savings Discriminant: IF income > 1 AND savings > 2 THEN low-risk ELSE high-risk 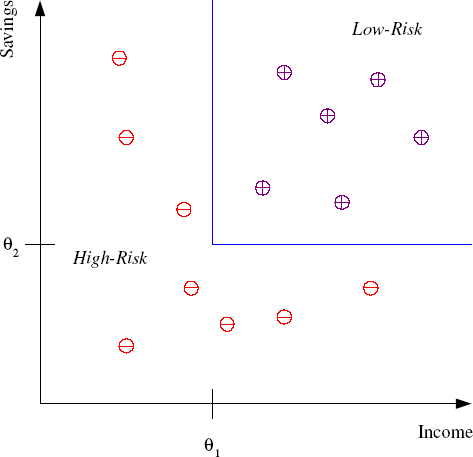 Prediction - Regression: Example: Predict Price of a used car x : car attributes y : price y = g ( x | ) where, g ( ) is the model, are the parameters
Prediction - Regression: Example: Predict Price of a used car x : car attributes y : price y = g ( x | ) where, g ( ) is the model, are the parameters 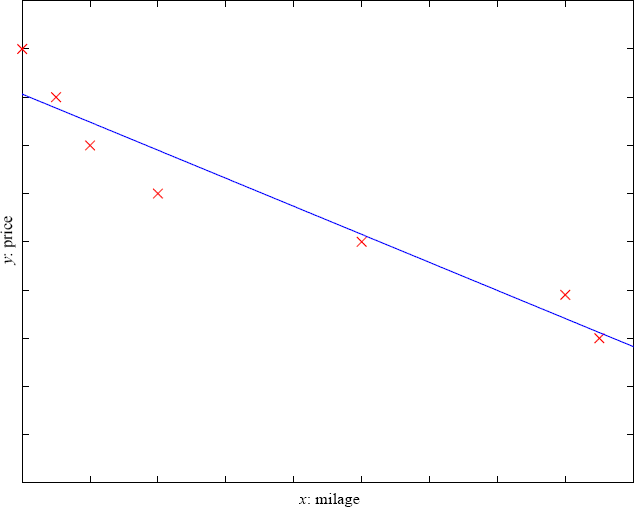 A training dataset of used cars and the function fitted.
A training dataset of used cars and the function fitted.
For simplicity,mileage is taken as the only input attribute and a linear model is used. Supervised Learning: Learning a Class from Examples: Class C of a family car
- Prediction: Is car x a family car?
- Knowledge extraction: What do people expect from a family car?
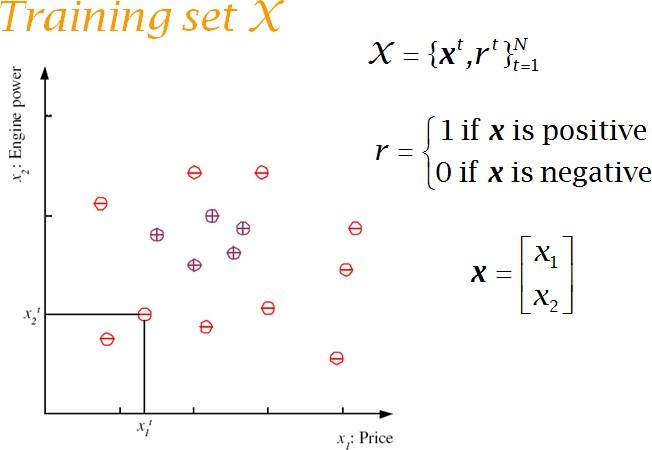
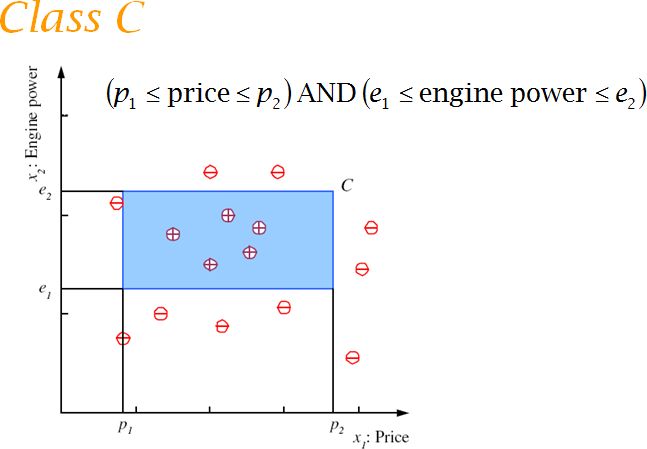
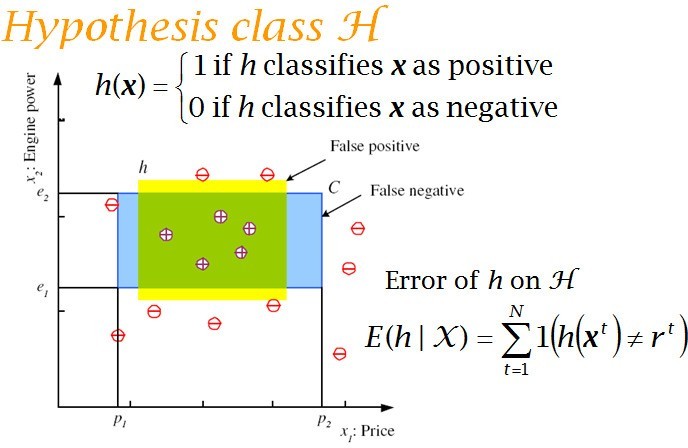
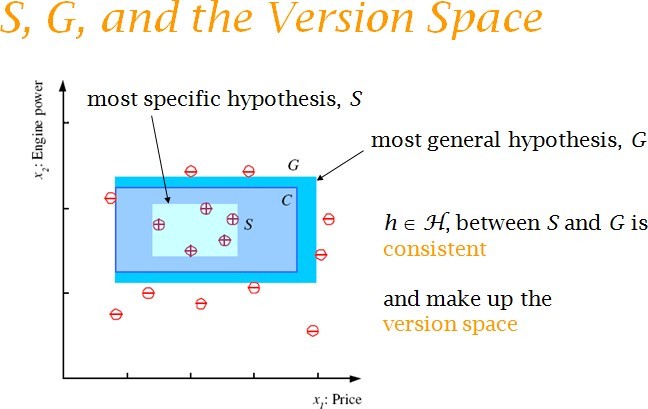 Probably Approximately Correct (PAC): Cannot expect a learner to learn a concept exactly. Cannot always expect to learn a close approximation to the target concept Therefore, the only realistic expectation of a good learner is that with high probability it will learn a close approximation to the target concept. In Probably Approximately Correct (PAC) learning, one requires that given small parameters and , with probability at least (1- ) a learner produces a hypothesis with error at most The reason we can hope for that is the Consistent Distribution assumption. PAC Learnability Consider a concept class C defined over an instance space X (containing instances of length n), and a learner L using a hypothesis space H. C is PAC learnable by L using H if o for all f C, o for all distributions D over X, and fixed 0< , < 1, L, given a collection of m examples sampled independently according to D produces o with probability at least (1- ) a hypothesis h H with error at most , (ErrorD = PrD[f(x) : = h(x)]) where m is polynomial in 1/ , 1/ , n and size(H) C is efficiently learnable if L can produce the hypothesis in time polynomial in 1/ , 1/ , n and size(H) We impose two limitations: Polynomial sample complexity (information theoretic constraint) o Is there enough information in the sample to distinguish a hypothesis h that approximate f ? Polynomial time complexity (computational complexity) o Is there an efficient algorithm that can process the sample and produce a good hypothesis h ? To be PAC learnable, there must be a hypothesis h H with arbitrary small error for every f C.Next page
Probably Approximately Correct (PAC): Cannot expect a learner to learn a concept exactly. Cannot always expect to learn a close approximation to the target concept Therefore, the only realistic expectation of a good learner is that with high probability it will learn a close approximation to the target concept. In Probably Approximately Correct (PAC) learning, one requires that given small parameters and , with probability at least (1- ) a learner produces a hypothesis with error at most The reason we can hope for that is the Consistent Distribution assumption. PAC Learnability Consider a concept class C defined over an instance space X (containing instances of length n), and a learner L using a hypothesis space H. C is PAC learnable by L using H if o for all f C, o for all distributions D over X, and fixed 0< , < 1, L, given a collection of m examples sampled independently according to D produces o with probability at least (1- ) a hypothesis h H with error at most , (ErrorD = PrD[f(x) : = h(x)]) where m is polynomial in 1/ , 1/ , n and size(H) C is efficiently learnable if L can produce the hypothesis in time polynomial in 1/ , 1/ , n and size(H) We impose two limitations: Polynomial sample complexity (information theoretic constraint) o Is there enough information in the sample to distinguish a hypothesis h that approximate f ? Polynomial time complexity (computational complexity) o Is there an efficient algorithm that can process the sample and produce a good hypothesis h ? To be PAC learnable, there must be a hypothesis h H with arbitrary small error for every f C.Next pageFont size:
Interval:
Bookmark:
Similar books «MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers»
Look at similar books to MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book MACHINE LEARNING: For BE/B.TECH/BCA/MCA/ME/M.TECH/Diploma/B.Sc/M.Sc/BBA/MBA/Competitive Exams & Knowledge Seekers and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.