Ayyadevara - Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R
Here you can read online Ayyadevara - Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. City: Berkeley;CA, year: 2018, publisher: Apress, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R
- Author:
- Publisher:Apress
- Genre:
- Year:2018
- City:Berkeley;CA
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Ayyadevara: author's other books
Who wrote Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R? Find out the surname, the name of the author of the book and a list of all author's works by series.









Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
- The difference between regression and classification
- The need for training, validation, and testing data
- The different measures of accuracy
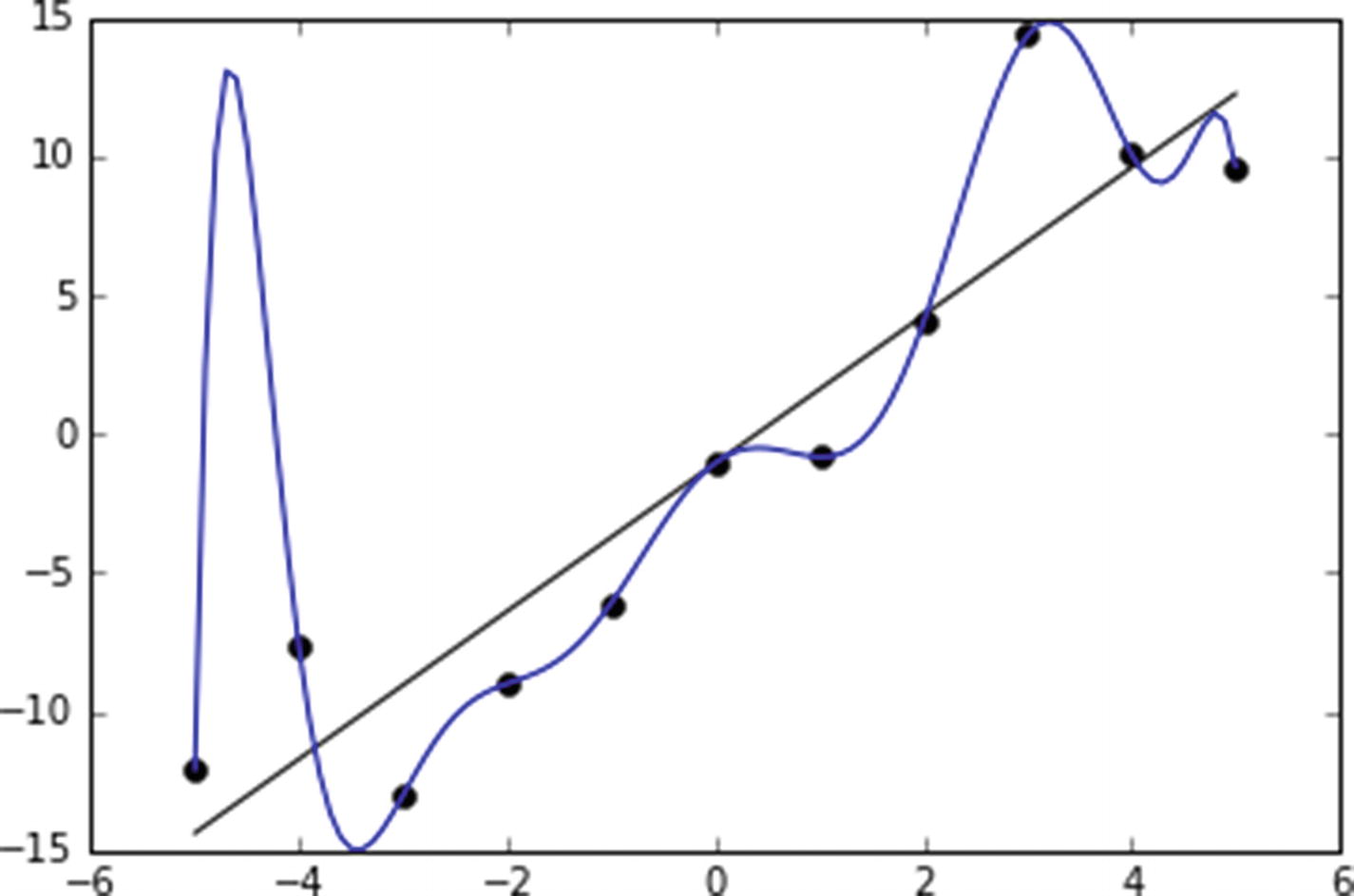
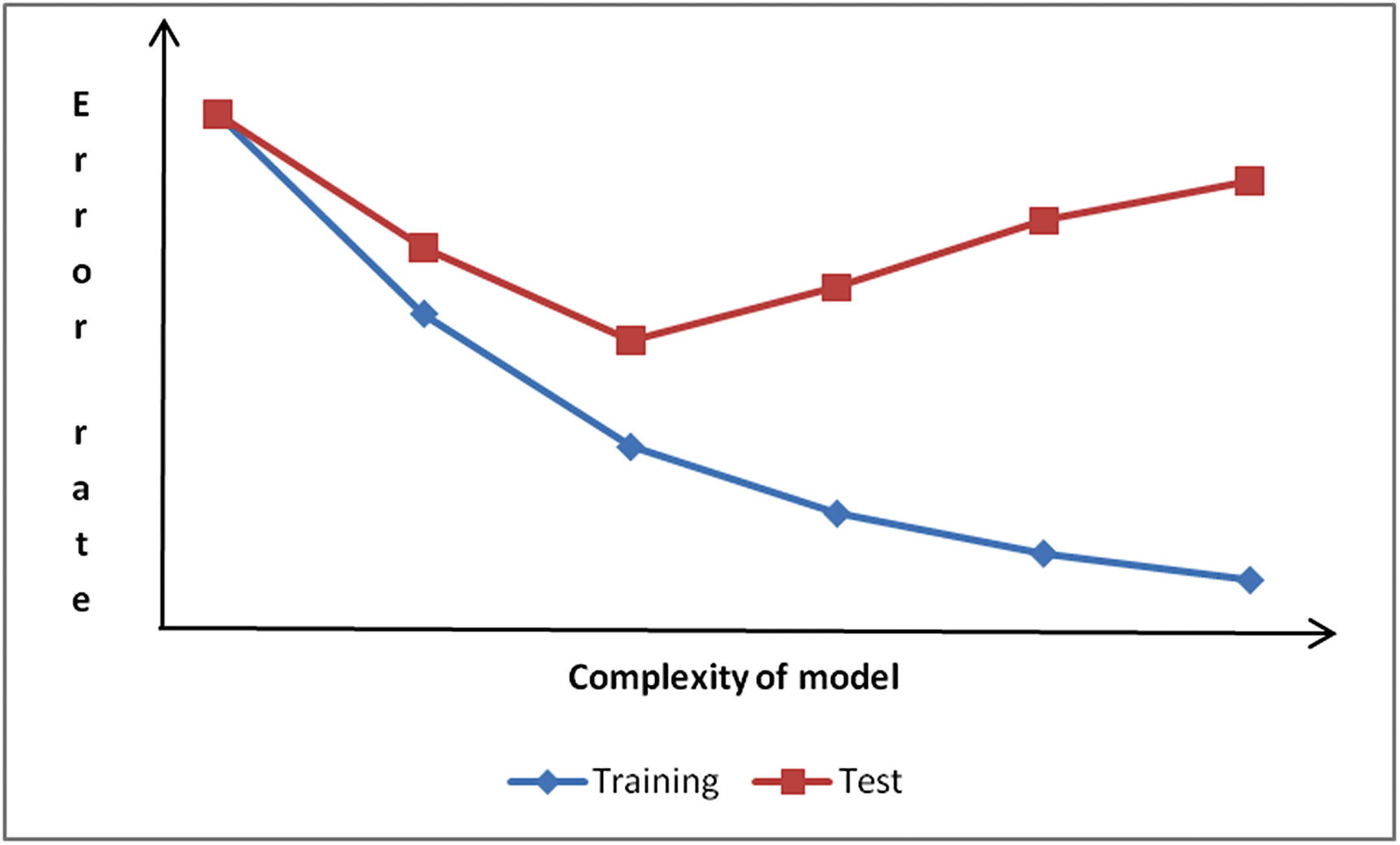
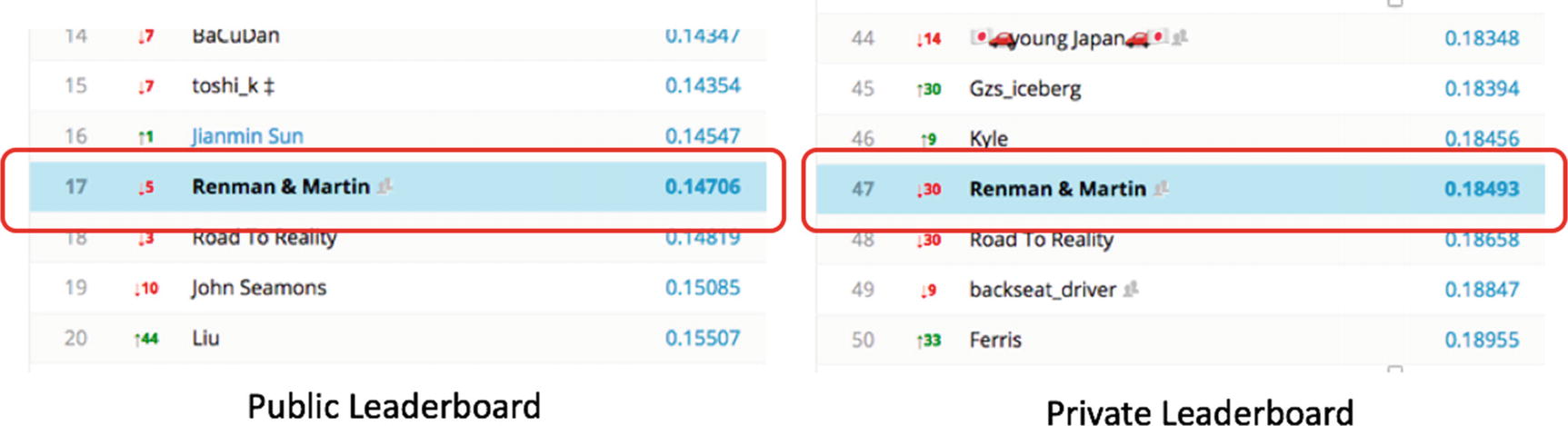
- We cannot test a models accuracy on the dataset on which it is trained.
- We cannot use the result of test dataset accuracy to finalize the ideal hyper-parameters, because, practically, the test dataset is unseen by the model.
Font size:
Interval:
Bookmark:
Similar books «Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R»
Look at similar books to Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Pro Machine Learning Algorithms: A Hands-On Approach to Implementing Algorithms in Python and R and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.