Wisdom - Predicting Security Threats with Splunk: Getting to Know Splunk
Here you can read online Wisdom - Predicting Security Threats with Splunk: Getting to Know Splunk full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2016, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

Predicting Security Threats with Splunk: Getting to Know Splunk: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Predicting Security Threats with Splunk: Getting to Know Splunk" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Wisdom: author's other books
Who wrote Predicting Security Threats with Splunk: Getting to Know Splunk? Find out the surname, the name of the author of the book and a list of all author's works by series.







Predicting Security Threats with Splunk: Getting to Know Splunk — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Predicting Security Threats with Splunk: Getting to Know Splunk" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:
As the complexity of organizations increases, new challenges arise when it comes to preventing security threats.
There is an undiscussed need for new proactive approaches in detecting potential security threats, to complement the traditional static analysis; in fact, threat signals might be intercepted by simply listening to network traffic, putting in place Introusion Detection Systems, stateful inspection, etc, by implementing appropriate hardware and software solutions.
However, in order to gain a complete and wider picture about whats going on, we need a different holistic mindset, achieved by leveraging on heterogeneous sources of information: thats what Big Data solutions, such as Splunk, are meant for.
Lets delve deeper.
You may have already heard of Big Data, but probably not in relation with IT Security: although Big Data is often associated with social media, actually it is much more than that; so lets recall some concepts regarding Big Data Analytics, before looking at their implementation in Splunk.
Conventionally, Big Data are characterized by the three Vs: Volumes,Velocity, and Variety.
- Volume of data (in terms of data storaging magnitude): the order of magnitude of data is usually considered starting from Petabytes to Zettabytes (and over). As more and more data are generated on a daily basis, Volume seems not to be a complete and appropriate criterion to tell Big Data apart from other normal data: as a matter of fact, as storage capabilities increase, along with their costs falling down, the Volume magnitude factor shifts constantly upwards;
- Velocity of data: is the speed at which data are generated or, on the other hand, the frequency at which data are delivered to organizations. As new hardware devices are put in place (sensors, cameras, rfid, even clickstream of web sites, etc), the stream of data at our disposal flows at higher rate then ever before, demanding for a real time approach in getting rid of informations hidden in data streams.
- Variety of data , has not only to do with different data sources, but also with their inherently unstructured format: it is controversial if data could be at all considered as unstructured as per their nature, or if it is instead the lacking of information about metadata that leads to unpredictable models.
Nevertheless, even when we try to analyze well known textual objects, such as emails (that are structured in compliance with RFC-2822, for example), we cannot be sure if they come in a predefined model or schema (for example, we cannot predict how long the email body field would be, or if a Subject field would be present or not, and so on).
The aforementioned characteristics may be summarized into a single concept: the need for scalability.
In fact, what really distinguish Big Data from Relational databases, for example, is that the latter dont scale very well when the magnitude of data increases exponentially, or when data streams produced by hardware appliances (over)flow in real time fashion, or data themself dont seem to comply with predefined and rigid schemas.
To work correctly, Relational databases need predefined data models with clearly defined fields in associated tables; in a very sense, Relational database conform to User driven data analytics, implying the so-called Early Structure Binding of data; in other words, the analyst needs to know in advance what kind of questions are to be answered by analyzing the data, so that the database design, including the schema and the structure of data, could be arranged in a predefined and appropriate format, in order for the questions to be answered correctly.
Instead, in a data driven context, such as Big Data Analytics, we let the data speak for themself: without imposing a predefined schema to data, we can freely rearrange their format at real time, reflecting the correlations (hidden insights) that may arise, letting the analyst focus the attention on appropriate variables, as their relevance becomes evident as the flow of data from different sources are merged together to form a whole new domain of research.
As an event indexer, Splunk can perform real-time data collecting, indexing and searching, managing structured and unstructured textual data, both user-generated (i.e. Social media) and machine-generated (hardware appliances, sensors, etc): By handling the Three Vs very well, Splunk essentially offers three main (and autonomous scalable) functionalities:
- Data collection: The first step in using Splunk is to feed it with data. Basically, you point Splunk at data and it does the rest. In moments, you can start searching the data, or use it to create charts, reports, alerts, and other interesting outputs. Splunk can manage any kind of data; in particular, all IT streaming and historical data ( such as event logs, web logs, live application logs, network feeds, system metrics, change monitoring, message queues, archive files, and so on). The data may reside on the same machine as the Splunk indexer (local data), or they can be located on another machine altogether (remote data).
- Data indexing: Once Splunk gets data, it immediately indexes them, so that they are available for searching. Splunk can index any type of time-series data (i.e. data with timestamps); leveraging on its universal indexing ability, Splunk transforms data into a series of individual events, consisting of searchable fields: this task is also known as event processing.Event processing occurs in two stages, parsing and indexing. During parsing, Splunk breaks data chunks into events which it hands off to the indexing pipeline, where final processing occurs (Figure 1).
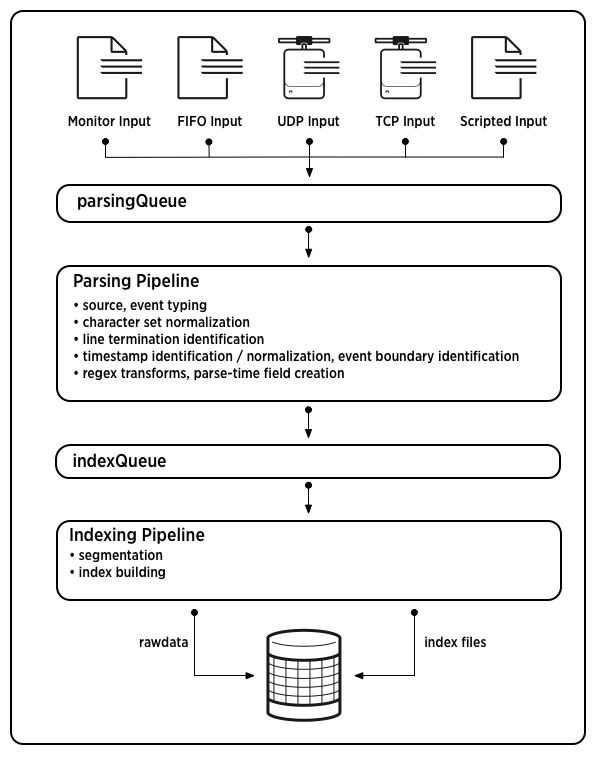
- Data Search: once the data is indexed, you can begin searching it and manipulating the results using the Splunk Search Language (SPL); the search command permits the use of keywords, phrases, fields, boolean expressions, along with comparison expressions, helping the analyst specifying exactly which events they want to retrieve from Splunk index(es).
To start searching, you need to point your browser to Splunk Home, i.e. the interactive portal to apps and data accessible from the Splunk instance (please note that Splunk Web interface is at http://localhost:8000), as in Figure 2:
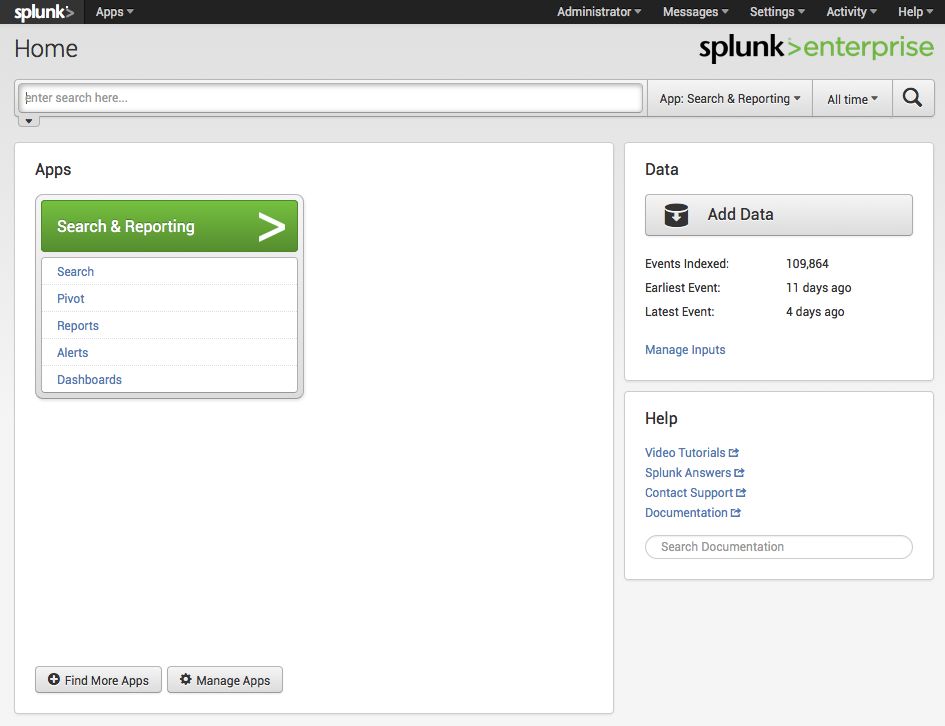 (Figure 2)
(Figure 2) In the Apps panel, you will see workspaces for the apps that are installed on your Splunk server that you have permission to view. The workspace displays a menu of the views and objects in the app context. Select the App to open it or select a content page listed in the workspace to go directly to that view. (Please note also the Data panel, that you can use to add data to Splunk).
Font size:
Interval:
Bookmark:
Similar books «Predicting Security Threats with Splunk: Getting to Know Splunk»
Look at similar books to Predicting Security Threats with Splunk: Getting to Know Splunk. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Predicting Security Threats with Splunk: Getting to Know Splunk and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.