1.1 Introduction
High-level languages, such as C, C++, and Java, are more like natural languages and thus make programs easier to read and write. Low-level languages are closer to the machine and there is a one-to-many relationship between high-level languages and low-level languages, where language translators such as compilers and interpreters convert each high-level instruction into many low-level instructions. The native language of a particular machine is a low-level language known as machine language and is coded in ones and zeros. Further, the machine language of an Intel microprocessor is different than that of other microprocessors or mainframes, thus machine language is not transferable from one type of machine to another.
Programming in machine language can be very tedious and error prone. Instead of using ones and zeros, an assembly language has an advantage, because it uses mnemonics (abbreviations) for the instructions and variable names for memory locations, instead of ones and zeros. There is also a one-to-one correspondence between the instructions in assembly language and in machine language. Programs can be written more easily in assembly language and do not have many of the disadvantages of programming in machine language. The advantage of programming in assembly language over a high-level language is that one can gain a very detailed look at the architecture of a computer system and write very efficient programs, in terms of both increasing speed and saving memory.
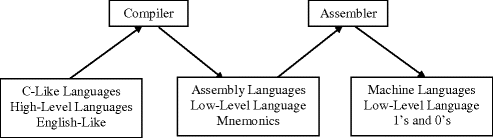
Just as compilers convert a high-level language to a low-level language, an assembler converts assembly language to machine language. Although some newer compilers convert high-level languages (such as Java) to an intermediate language (such as bytecode) which is then interpreted to machine language, the result is that the final code is in machine language of the machine the program is to be executed on. Figure illustrates how a language might be implemented.
Fig. 1.1
High-level language and assembly language translation to machine language
There are a number of assemblers available to convert to Intel machine language, but the one used in this text is MASM (Microsoft Assembler). The method used for installing, keying in an assembly program, assembling a program, and executing a program will probably be explained by ones instructor or might be demonstrated by colleagues at ones place of employment. However, if one is reading this text independently and wants to install the software on a home computer, the instructions can be found in Appendix A.
When learning any new programming language, whether high level or low level, it is helpful to start with a very simple program. Often when learning a high-level language, the first program is the infamous Hello World program, which when keyed in allows the programmer to have a correctly compiled and executable program. Unfortunately, when starting to learn a low-level language, the input/output (I/O) facilities are much more complicated and it is usually not the best place to start. As a result, this text will first look at some of the fundamentals of assembly language and then subsequently examine I/O to verify that the fundamentals have been learned and implemented properly.
1.2 The First Program
The first program to be implemented will be the equivalent of the following C program, which merely declares two variables, assigns a value to the first variable, and then assigns the contents of the first variable to the second variable: int main(){ int num1,num2; num1=5; num2=num1; return 0; }
What follows is an assembly language program that implements the same logic as the C program above. Although at first it might look a little intimidating, it can serve as a useful starting point in learning the basic layout and format of an assembly language program:
.386 .model flat, c .stack 100 h .data num1 sdword ? ; first number num2 sdword ? ; second number .code main proc mov num1,5 ; initialize num1 with 5 mov eax,num1 ; load eax with contents of num1 mov num2,eax ; store eax in num2 ret main endp end
The first thing to be understood is that some of the statements above are directives , while others are instructions . Although it will be discussed in more detail later, simply put, instructions tell the central processing unit ( CPU ) what to do, whereas directives tell the assembler what to do. Similar to directives, operators also tell the assembler what to do with a particular instruction.
The .386 at the beginning of the program is a directive and indicates that the program should be assembled as though the program will be run on an Intel 386 or newer processor, such as Pentiums and 64-bit machines. It is possible to specify that older processors could be used, but the .286 and older processors were 16-bit machines and did not have as many features as the .386, which is a 32-bit machine. Although a newer processor could be specified, there are not a significant number of newer instructions that will be covered in this text and using .386 would still allow the program to be run on some older processors.
The .model flat directive specifies that the program uses protected mode which indicates that 32-bit addresses will be used and thus it is possible to address 4 GB of memory. Although there exist some previous forms of addressing, this protected mode is fairly common now, is simpler to understand, and can address more memory. The c in the model directive indicates that it can link with C and C++ programs and is needed to run in the Visual C++ environment.
The .stack directive indicates the size of the stack in hexadecimal (see Appendix B) and indicates the stack should be 100 hexadecimal bytes large, or 256 bytes. The use of the stack will be discussed later in . The .data and .code directives will be discussed shortly, but the proc directive stands for procedure and indicates that the name of the procedure is main . Although other names can be used, the name main is similar to naming a C, C++, or Java program main and allows the assembly program to be run independently of other programs. The ret instruction serves as a return 0 statement does in C or C++. The main endp label and directive indicate the end of the procedure and the end directive indicates the end of the program for the assembler.