Paco Nathan - Enterprise Data Workflows with Cascading
Here you can read online Paco Nathan - Enterprise Data Workflows with Cascading full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2013, publisher: OReilly Media, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Enterprise Data Workflows with Cascading
- Author:
- Publisher:OReilly Media
- Genre:
- Year:2013
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Enterprise Data Workflows with Cascading: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Enterprise Data Workflows with Cascading" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
There is an easier way to build Hadoop applications. With this hands-on book, youll learn how to use Cascading, the open source abstraction framework for Hadoop that lets you easily create and manage powerful enterprise-grade data processing applicationswithout having to learn the intricacies of MapReduce.
Working with sample apps based on Java and other JVM languages, youll quickly learn Cascadings streamlined approach to data processing, data filtering, and workflow optimization. This book demonstrates how this framework can help your business extract meaningful information from large amounts of distributed data.
- Start working on Cascading example projects right away
- Model and analyze unstructured data in any format, from any source
- Build and test applications with familiar constructs and reusable components
- Work with the Scalding and Cascalog Domain-Specific Languages
- Easily deploy applications to Hadoop, regardless of cluster location or data size
- Build workflows that integrate several big data frameworks and processes
- Explore common use cases for Cascading, including features and tools that support them
- Examine a case study that uses a dataset from the Open Data Initiative
Paco Nathan: author's other books
Who wrote Enterprise Data Workflows with Cascading? Find out the surname, the name of the author of the book and a list of all author's works by series.













Enterprise Data Workflows with Cascading — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Enterprise Data Workflows with Cascading" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

Beijing Cambridge Farnham Kln Sebastopol Tokyo
Download from Wow! eBook
If you purchased this ebook directly from oreilly.com, you have the following benefits:
DRM-free ebooksuse your ebooks across devices without restrictions or limitations
Multiple formatsuse on your laptop, tablet, or phone
Lifetime access, with free updates
Dropbox syncingyour files, anywhere
If you purchased this ebook from another retailer, you can upgrade your ebook to take advantage of all these benefits for just $4.99. to access your ebook upgrade.
Please note that upgrade offers are not available from sample content.
Throughout this book, we will explore Cascading and related open source projects in the context of brief programming examples.Familiarity with Java programming is required.Well show additional code in Clojure, Scala, SQL, and R.The sample apps are all available in source code repositories on GitHub.These sample apps are intended to run on a laptop (Linux, Unix, and Mac OS X, but not Windows) using Apache Hadoop in standalone mode.Each example is built so that it will run efficiently with a large data set on a large cluster, but setting new world records on Hadoop isnt our agenda.Our intent here is to introduce a new way of thinking about how Enterprise apps get designed.We will show how to get started with Cascading and discuss best practices for Enterprise data workflows.
Cascading provides an open source API for writing Enterprise-scale apps on top of Apache Hadoop and other Big Data frameworks.In production use now for five years (as of 2013Q1), Cascading apps run at hundreds of different companiesand in several verticals, which include finance, retail, health care, and transportation.Case studies have been published about large deployments atWilliams-Sonoma, Twitter, Etsy, Airbnb, Square, The Climate Corporation, Nokia, Factual, uSwitch, Trulia, Yieldbot, and the Harvard School of Public Health.Typical use cases for Cascading include large extract/transform/load (ETL) jobs,reporting, web crawlers, anti-fraud classifiers, social recommender systems, retail pricing, climate analysis, geolocation, genomics,plus a variety of other kinds of machine learning and optimization problems.
Keep in mind that Apache Hadoop rarely if ever gets used in isolation.Generally speaking, apps that run on Hadoop must consume data from a variety of sources,and in turn they produce data that must be used in other frameworks.For example, a hypothetical social recommender shown in to be served through an API.Cascading encompasses the schema and dependencies for each of those components in a workflowdata sources for input, business logic in the application, the flows that define parallelism, rules for handling exceptions, data sinks for end uses, etc.The problem at hand is much more complex than simply a sequence of Hadoop job steps.
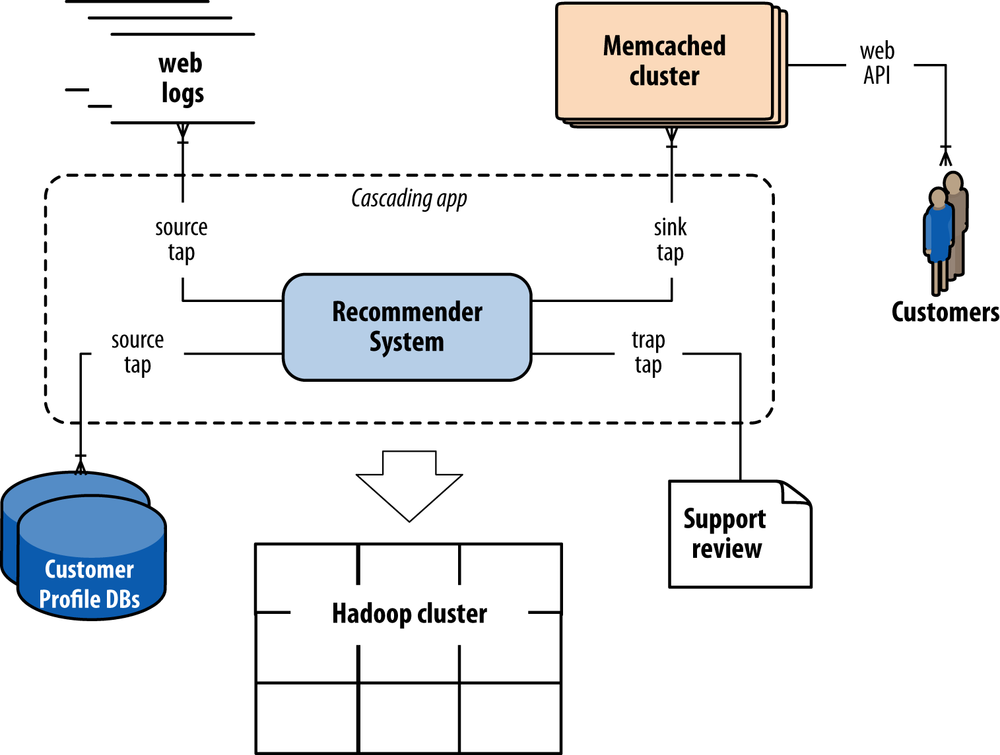
Moreover, while Cascading has been closely associated with Hadoop, it is not tightly coupled to it.Flow planners exist for other topologies beyond Hadoop, such as in-memory data grids for real-time workloads.That way a given app could compute some parts of a workflow in batch and some in real time,while representing a consistent unit of work for scheduling, accounting, monitoring, etc.The system integration of many different frameworks means that Cascading apps define comprehensive workflows.
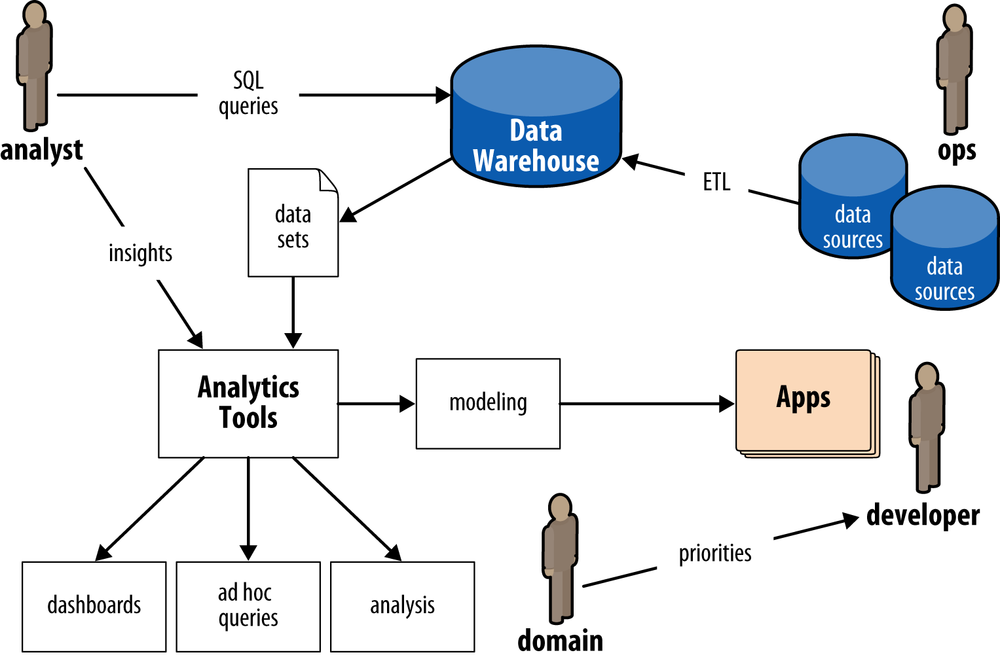
Circa early 2013, many Enterprise organizations are building out their Hadoop practices.There are several reasons, but for large firms the compelling reasons are mostly economic.Lets consider a typical scenario for Enterprise data workflows prior to Hadoop, shown in .
An analyst typically would make a SQL query in a data warehouse such as Oracle or Teradata to pull a data set.That data set might be used directly for a pivot tables in Excel for ad hoc queries,or as a data cube going into a business intelligence (BI) server such as Microstrategy for reporting.In turn, a stakeholder such as a product owner would consume that analysis via dashboards, spreadsheets, or presentations.Alternatively, an analyst might use the data in an analytics platform such as SAS for predictive modeling,which gets handed off to a developer for building an application.Ops runs the apps, manages the data warehouse (among other things), and oversees ETL jobs that load data from other sources.Note that in this diagram there are multiple componentsdata warehouse, BI server, analytics platform, ETLwhich have relatively expensive licensing and require relatively expensive hardware.Generally these apps scale up by purchasing larger and more expensive licenses and hardware.
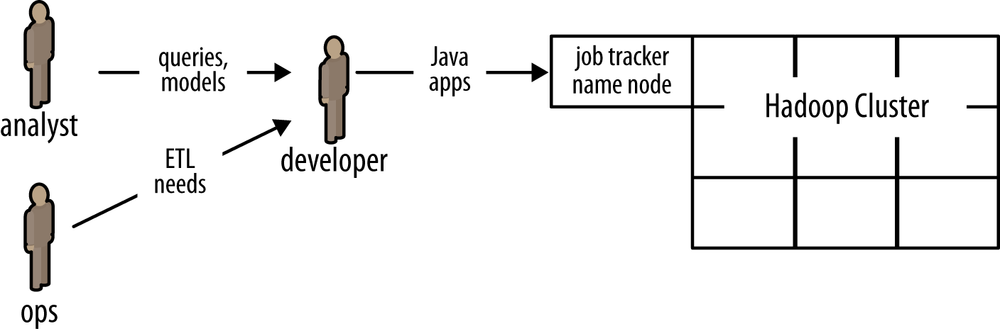
Circa late 1997 there was an inflection point,after which a handful of pioneering Internet companies such as Amazon the developers with Hadoop expertise become a new kind of bottleneck for analysts and operations.
Enterprise adoption of Apache Hadoop, driven by huge savings and opportunities for new kinds of large-scale data apps,has increased the need for experienced Hadoop programmers disproportionately.Theres been a big push to train current engineers and analysts and to recruit skilled talent.However, the skills required to write large Hadoop apps directly in Java are difficult to learn for most developers and far outside the norm of expectations for analysts.Consequently the approach of attempting to retrain current staff does not scale very well.Meanwhile, companies are finding that the process of hiring expert Hadoop programmers is somewhere in the range of difficult to impossible.That creates a dilemma for staffing, as Enterprise rushes to embrace Big Data and Apache Hadoop:SQL analysts are available and relatively less expensive than Hadoop experts.
An alternative approach is to use an abstraction layer on top of Hadoopone that fits well with existing Java practices.Several leading IT publications have described Cascading in those terms, for example:
Management can really go out and build a team around folks that are already very experienced with Java.Switching over to this is really a very short exercise.
Thor OlavsrudCIO magazine (2012)
Cascading recently added support for ANSI SQL through a library called Lingual.Another library called Pattern supports thePredictive Model Markup Language (PMML),which is used by most major analytics and BI platforms to export data mining models.Through these extensions, Cascading provides greater access to Hadoop resources for the more traditional analysts as well as Java developers.Meanwhile, other projects atop Cascadingsuch as Scalding (based on Scala) and Cascalog (based on Clojure)are extending highly sophisticated software engineering practices to Big Data.For example, Cascalog provides features fortest-driven development (TDD) of Enterprise data workflows.
Font size:
Interval:
Bookmark:
Similar books «Enterprise Data Workflows with Cascading»
Look at similar books to Enterprise Data Workflows with Cascading. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Enterprise Data Workflows with Cascading and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.