Ramcharan Kakarla - Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle
Here you can read online Ramcharan Kakarla - Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. publisher: Apress, genre: Computer. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle
- Author:
- Publisher:Apress
- Genre:
- Rating:3 / 5
- Favourites:Add to favourites
- Your mark:
Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Ramcharan Kakarla: author's other books
Who wrote Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle? Find out the surname, the name of the author of the book and a list of all author's works by series.





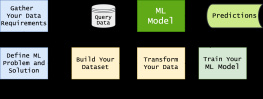







Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

Any source code or other supplementary material referenced by the author in this book is available to readers on GitHub via the books product page, located at www.apress.com/978-1-4842-6499-7 . For more detailed information, please visit http://www.apress.com/source-code .
Goutam Chakraborty(Ph.D., University of Iowa) is Professor of Marketing in the Spears School of Business at Oklahoma State University. His research has been published in scholarly journals such as Journal of Interactive Marketing, Journal of Advertising Research, Journal of Advertising, Journal of Business Research, and Industrial Marketing Management, among others. Goutam teaches a variety of courses, including digital business strategy, electronic commerce and interactive marketing, data mining and CRM applications, data base marketing, and advanced marketing research. He has won many teaching awards including Regents Distinguished Teaching Award at O.S.U, Outstanding Direct Marketing Educator Award given by the Direct Marketing Educational Foundation, Outstanding Marketing Teacher Award given by Academy of Marketing Science, and USDLA Best practice Bronze Award for Excellence in Distance Learning given by United States Distance Learning Association. He has consulted with numerous companies and has presented programs and workshops worldwide to executives, educators, and research professionals.
No matter where you live in the world today or which industry you work for, your present and future is inundated with messy data all around you. The big questions of the day are what you are going to do with all these messy data? and how would you analyze these messy data using a scalable, parallel processing platform? I believe this book helps you with answering both of those big questions in an easy to understand style.
I am delighted to write the foreword for the book titled Applied Data Science Using PySpark by Ramcharan Kakarla and Sundar Krishnan. Let me say at the outset that I am very positively biased towards the authors because they are graduates of our program at Oklahoma State University and have been through several of my classes. As a professor, nothing pleases me more than when I see my students excel in their lives. The book is a prime example of when outstanding students continue their life long learning and give back to the community of learners their combined experiences in using PySpark for data science.
Goutam Chakraborty, Ph.D.
Futoshi Yumotois actively involved in health outcome research as an affiliated scholar at Collaborative for Research on Outcomes and Metrics (CROM:https://blogs.commons.georgetown.edu/crom/), and consistently contributes to scientific advancement through publications and presentations
I really could have used a book like this when I was learning to use PySpark. In my day-to-day work as a data scientist, I plan to use this book as a resource to prototype PySpark codes while I plan to share this book with my team members, to make sure they are easily able to make the most of PySpark from their initial engagement, I can also see this being used as a textbook for a consulting course or certification program.
Currently there are dozens of books with similar titles that are available, but this is the first one I have seen that helps you to set up PySpark environment and execute operation ready codes within a matter of day with sufficient examples, sample data and codes. It leaves the option open for a reader to delve more deeply (and provides up to date references as well as historical ones), while concisely explaining in concrete steps how to apply the program in a variety of problem types/use cases. I have been asked many times for introductory but practical materials to help orient data scientists who needs to transition to PySpark from Python, and this is the first book I am happy to recommend.
This book started as authors project in 2020 and has grown into an organic, but instructive, resource that any data scientist can utilize. Data science is a fast-evolving, multi-dimensional discipline. PySpark has emerged from Spark (define) to help Python users exploit the speed and computational capabilities of Spark. Although this book is focused on Pyspark, through its introduction to both Python and Spark, the authors have crafted a self-directed learning resource that can be generalized to help teach data science principles to individuals at any career stage.
Font size:
Interval:
Bookmark:
Similar books «Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle»
Look at similar books to Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Applied Data Science Using PySpark: Learn the End-to-End Predictive Model-Building Cycle and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.