Charu C. Aggarwal - Linear Algebra and Optimization for Machine Learning: A Textbook
Here you can read online Charu C. Aggarwal - Linear Algebra and Optimization for Machine Learning: A Textbook full text of the book (entire story) in english for free. Download pdf and epub, get meaning, cover and reviews about this ebook. year: 2020, publisher: Springer Nature, genre: Home and family. Description of the work, (preface) as well as reviews are available. Best literature library LitArk.com created for fans of good reading and offers a wide selection of genres:
Romance novel
Science fiction
Adventure
Detective
Science
History
Home and family
Prose
Art
Politics
Computer
Non-fiction
Religion
Business
Children
Humor
Choose a favorite category and find really read worthwhile books. Enjoy immersion in the world of imagination, feel the emotions of the characters or learn something new for yourself, make an fascinating discovery.

- Book:Linear Algebra and Optimization for Machine Learning: A Textbook
- Author:
- Publisher:Springer Nature
- Genre:
- Year:2020
- Rating:4 / 5
- Favourites:Add to favourites
- Your mark:
Linear Algebra and Optimization for Machine Learning: A Textbook: summary, description and annotation
We offer to read an annotation, description, summary or preface (depends on what the author of the book "Linear Algebra and Optimization for Machine Learning: A Textbook" wrote himself). If you haven't found the necessary information about the book — write in the comments, we will try to find it.
Charu C. Aggarwal: author's other books
Who wrote Linear Algebra and Optimization for Machine Learning: A Textbook? Find out the surname, the name of the author of the book and a list of all author's works by series.












Linear Algebra and Optimization for Machine Learning: A Textbook — read online for free the complete book (whole text) full work
Below is the text of the book, divided by pages. System saving the place of the last page read, allows you to conveniently read the book "Linear Algebra and Optimization for Machine Learning: A Textbook" online for free, without having to search again every time where you left off. Put a bookmark, and you can go to the page where you finished reading at any time.
Font size:
Interval:
Bookmark:

This Springer imprint is published by the registered company Springer Nature Switzerland AG
The registered company address is: Gewerbestrasse 11, 6330 Cham, Switzerland
To my wife Lata, my daughter Sayani, and all my mathematics teachers
Mathematics is the language with which God wrote the universe. Galileo
A frequent challenge faced by beginners in machine learning is the extensive background required in linear algebra and optimization. One problem is that the existing linear algebra and optimization courses are not specific to machine learning; therefore, one would typically have to complete more course material than is necessary to pick up machine learning. Furthermore, certain types of ideas and tricks from optimization and linear algebra recur more frequently in machine learning than other application-centric settings. Therefore, there is significant value in developing a view of linear algebra and optimization that is better suited to the specific perspective of machine learning.
It is common for machine learning practitioners to pick up missing bits and pieces of linear algebra and optimization via osmosis while studying the solutions to machine learning applications. However, this type of unsystematic approach is unsatisfying, because the primary focus on machine learning gets in the way of learning linear algebra and optimization in a generalizable way across new situations and applications. Therefore, we have inverted the focus in this book, with linear algebra and optimization as the primary topics of interest and solutions to machine learning problems as the applications of this machinery.In other words, the book goes out of its way to teach linear algebra and optimization with machine learning examples. By using this approach, the book focuses on those aspects of linear algebra and optimization that are more relevant to machine learning and also teaches the reader how to apply them in the machine learning context. As a side benefit, the reader will pick up knowledge of several fundamental problems in machine learning. At the end of the process, the reader will become familiar with many of the basic linear-algebra- and optimization-centric algorithms in machine learning. Although the book is not intended to provide exhaustive coverage of machine learning, it serves as a technical starter for the key models and optimization methods in machine learning. Even for seasoned practitioners of machine learning, a systematic introduction to fundamental linear algebra and optimization methodologies can be useful in terms of providing a fresh perspective.
Linear algebra and its applications:The chapters focus on the basics of linear algebra together with their common applications to singular value decomposition, matrix factorization, similarity matrices (kernel methods), and graph analysis. Numerous machine learning applications have been used as examples, such as spectral clustering, kernel-based classification, and outlier detection. The tight integration of linear algebra methods with examples from machine learning differentiates this book from generic volumes on linear algebra. The focus is clearly on the most relevant aspects of linear algebra for machine learning and to teach readers how to apply these concepts.
Optimization and its applications:Much of machine learning is posed as an optimization problem in which we try to maximize the accuracy of regression and classification models. The parent problem of optimization-centric machine learning is least-squares regression. Interestingly, this problem arises in both linear algebra and optimization and is one of the key connecting problems of the two fields. Least-squares regression is also the starting point for support vector machines, logistic regression, and recommender systems. Furthermore, the methods for dimensionality reduction and matrix factorization also require the development of optimization methods. A general view of optimization in computational graphs is discussed together with its applications to backpropagation in neural networks.
Throughout this book, a vector or a multidimensional data point is annotated with a bar, such as 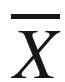 or
or 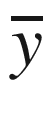 . A vector or multidimensional point may be denoted by either small letters or capital letters, as long as it has a bar. Vector dot products are denoted by centered dots, such as
. A vector or multidimensional point may be denoted by either small letters or capital letters, as long as it has a bar. Vector dot products are denoted by centered dots, such as 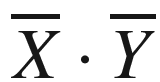 . A matrix is denoted in capital letters without a bar, such asR. Throughout the book, thendmatrix corresponding to the entire training data set is denoted by
. A matrix is denoted in capital letters without a bar, such asR. Throughout the book, thendmatrix corresponding to the entire training data set is denoted by
Font size:
Interval:
Bookmark:
Similar books «Linear Algebra and Optimization for Machine Learning: A Textbook»
Look at similar books to Linear Algebra and Optimization for Machine Learning: A Textbook. We have selected literature similar in name and meaning in the hope of providing readers with more options to find new, interesting, not yet read works.
Discussion, reviews of the book Linear Algebra and Optimization for Machine Learning: A Textbook and just readers' own opinions. Leave your comments, write what you think about the work, its meaning or the main characters. Specify what exactly you liked and what you didn't like, and why you think so.